

Ada yang penting untuk dijelaskan tentang temuan Riset Kesejahteraan Dosen yang dirilis tahun 2024, hasil survei ini menuai respon yang beragam. Salah satu yang cukup ramai dibicarakan adalah persoalan metodologi survei yang dianggap tidak cukup akurat menggambarkan populasi dosen.
Kritik adalah keniscayaan dalam komunikasi kesarjanaan. Tim peneliti dalam studi tersebut semuanya berprofesi sebagai ilmuwan penuh waktu, sehingga kesan saya, mereka sangat terbuka dengan kritik. Menurut anggota tim penelitian, sebagian kritik yang mereka terima juga disadari dan dipertimbangkan dengan serius apabila nanti mereka berencana melakukan studi lanjutan.
Yang menarik, perbincangan soal keterwakilan sampel ini cenderung gak grounded in principle kalau dari sudut pandang metodologi. Oleh karena itu, dalam tulisan ini, saya akan coba untuk menjelaskan sekaligus membongkar (..in a good faith) beberapa mitos mengenai keterwakilan dalam penelitian survei.
Oya, tulisan ini sumber utamanya dari bab buku yang saya tulis. Judulnya, “Metodologi Penelitian dalam Psikologi Politik,” yang dimuat dalam buku “Pengantar Psikologi Politik,” terbitan Kompas Gramedia.
Klik disini untuk preprint dan post-print naskah bab bukunya.

Keterwakilan itu sebenarnya apa sih?
Prinsipnya, penelitian survei itu mencoba untuk memotret kondisi suatu populasi dengan cara mempelajari sebagian kecil (subset) dari populasi tersebut. Nah, untuk menentukan siapa yang bisa mewakili populasi, peneliti biasanya akan melakukan proses sampling.
Dalam proses ini, agar prosesnya adil, peneliti akan memastikan bahwa seluruh anggota populasi punya kesempatan yang sama untuk terpilih.
Gimana caranya agar seluruh anggota populasi punya kesempatan yang sama?
Peneliti akan melakukan pengacakan atau randomisasi.
Misalnya, kalau populasi yang kita teliti adalah komunitas wibu dengan 100 anggota, dan kita mau ambil 50 orang aja untuk diteliti, maka dengan melakukan pengacakan, setiap orang punya peluang yang sama (sebesar 50:50) untuk terpilih menjadi sampel. Teknik ini disebut juga sebagai probability sampling.
Untuk melakukan probability sampling, peneliti harus punya sampling frame, yaitu daftar seluruh anggota populasi. Sampling frame dijadikan dasar untuk melakukan pengacakan. Contoh sampling frame misalnya Daftar Pemilih Tetap (DPT) atau data kependudukan yang digunakan untuk merekrut partisipan survei elektabilitas.
Tetapi, pada banyak kejadian, sampling frame tidak tersedia. Kalaupun ada, umumnya sulit diakses peneliti kroco mumet. Nonprobability sampling menjadi opsi yang tidak bisa dihindari.
Dengan melakukan nonprobability sampling, peneliti harus pasrah desainnya terkontaminasi selection bias, yaitu kondisi yang terjadi ketika peluang anggota populasi untuk terpilih menjadi sampel menjadi berbeda atau bahkan tidak diketahui.
Kenapa selection bias ini menjadi masalah? Sebagian besar teknik statistik mengasumsikan semua anggota populasi memiliki peluang yang sama untuk menjadi sampel. Kalau terjadi selection bias, maka peneliti harus menggunakan teknik statistik yang tidak mengasumsikan hal ini. Meskipun ada, pilihannya tidak banyak.
Artinya, keterwakilan ini — dalam tingkat tertentu — berkaitan dengan akurasi temuan survei, yang diperoleh dari melakukan analisis statistik.
Kalau sudah melakukan pengacakan (probability sampling) apakah berarti sampel yang terpilih representatif? Harusnya iya dong.. Masak enggak sih?
Oh, tidak ada jaminan.
Pengacakan memang mengurangi selection bias, tetapi tidak selalu menghasilkan sampel yang representatif.
Bayangkan seorang peneliti sedang meneliti jumlah koleksi action figure anggota komunitas wibu yang jumlahnya 1000 orang. Anggota komunitas ini rentang usianya antara 18–70 tahun, kemudian sampel (10 orang) dipilih dengan menggunakan ballot — dikocok kaya menentukan pemenang arisan.
Sepuluh orang yang terpilih sebagai sampel rentang usianya ternyata 18–20 tahun, dan kemudian dari hasil penelitian disimpulkan pada ga punya action figure. Tentu tidak bisa diambil kesimpulan seperti ini, karena ya emang di usia 18–20 tahun umumnya belum punya pendapatan tetap sehingga mereka tidak bisa membeli action figure.
Selain itu, yang paling penting — rentang usia sampel (18–20 tahun) terlalu berbeda jauh sehingga tidak bisa mewakili keragaman di populasi (18–70 tahun). Jelas aja kesimpulannya menjadi tidak akurat.
Untuk mengatasi masalah seperti ini, bisa sih peneliti mempertimbangkan struktur populasi ketika melakukan proses sampling (misalnya, menggunakan stratified atau bahkan multistage sampling).
Tetapi, probability sampling seringkali tidak dilakukan simply karena peneliti tidak punya akses data seluruh anggota populasi (sampling frame).
Kesimpulan interimnya: kata kunci dari keterwakilan adalah variasi.
Variasi di sampel idealnya merefleksikan variasi di populasi.
Oh ya, dalam statistik, variasi adalah kunci. Penelitian kuantitatif — terlepas dari apapun desainnya, tujuan akhirnya adalah menyajikan atau menjelaskan variasi di dalam sampel.
Dalam statistik, variasi dalam sampel ini ditunjukkan oleh dispersi. Ada banyak pilihan strategi mengukur dispersi, misalnya: varians, rentang (range), jarak interkuartil, dsb. Tetapi yang paling lazim digunakan adalah simpangan baku (standar deviasi). Kenapa? Saya jelaskan alasannya disini.
Harapannya, dengan membandingkan variasi di sampel dan populasi, kita bisa mengira-ngira apa yang terjadi di populasi, hanya dengan mempelajari sampel.
Bagaimana kita tahu kalau sampel kita representatif?
Nah, ini pertanyaan utamanya. Penjelasan bagian ini agak panjang dan melibatkan sedikit matematika sederhana. Saya akan berusaha menjelaskannya sesederhana mungkin, tapi please bear with me😄
Bayangkan ada satu komunitas wibu dengan jumlah anggota 100 orang, dan semua orang, seratus-seratusnya berusia 18 tahun. Kalau populasinya tidak bervariasi seperti ini, satu orang aja sudah representatif mewakili 100 orang, lho.
Di kasus lain, di sekolah menengah dengan jumlah total siswa sebanyak 10.000 orang, sepuluhribu-sepuluhribunya berusia 16 tahun. Sama seperti kasus di atas, satu orang siswa (yang berusia 16 tahun) sudah cukup representatif mewakili seluruhnya.
Jadi, kalau ada yang bilang semakin besar ukuran populasinya (N), maka jumlah sampelnya (n) harus semakin besar — agar representatif. Ternyata, di kasus atas, tidak terjadi, kan?
Jumlah sampel yang sama (n = 1), masing-masing sama-sama representatif mewakili dua populasi, respectively, meskipun ukuran populasinya berbeda jauh.
Kesimpulannya —ukuran populasi (N) tidak penting untuk menentukan keterwakilan sampel. Membandingkan variasi (antara sampel dengan populasi) justru lebih tepat untuk menunjukkan keterwakilan.
Oke, sekarang kita tahu kalau cara yang tepat untuk tahu representatif engganya suatu sampel, melalui perbandingan antara varians sampel dengan varians populasi.
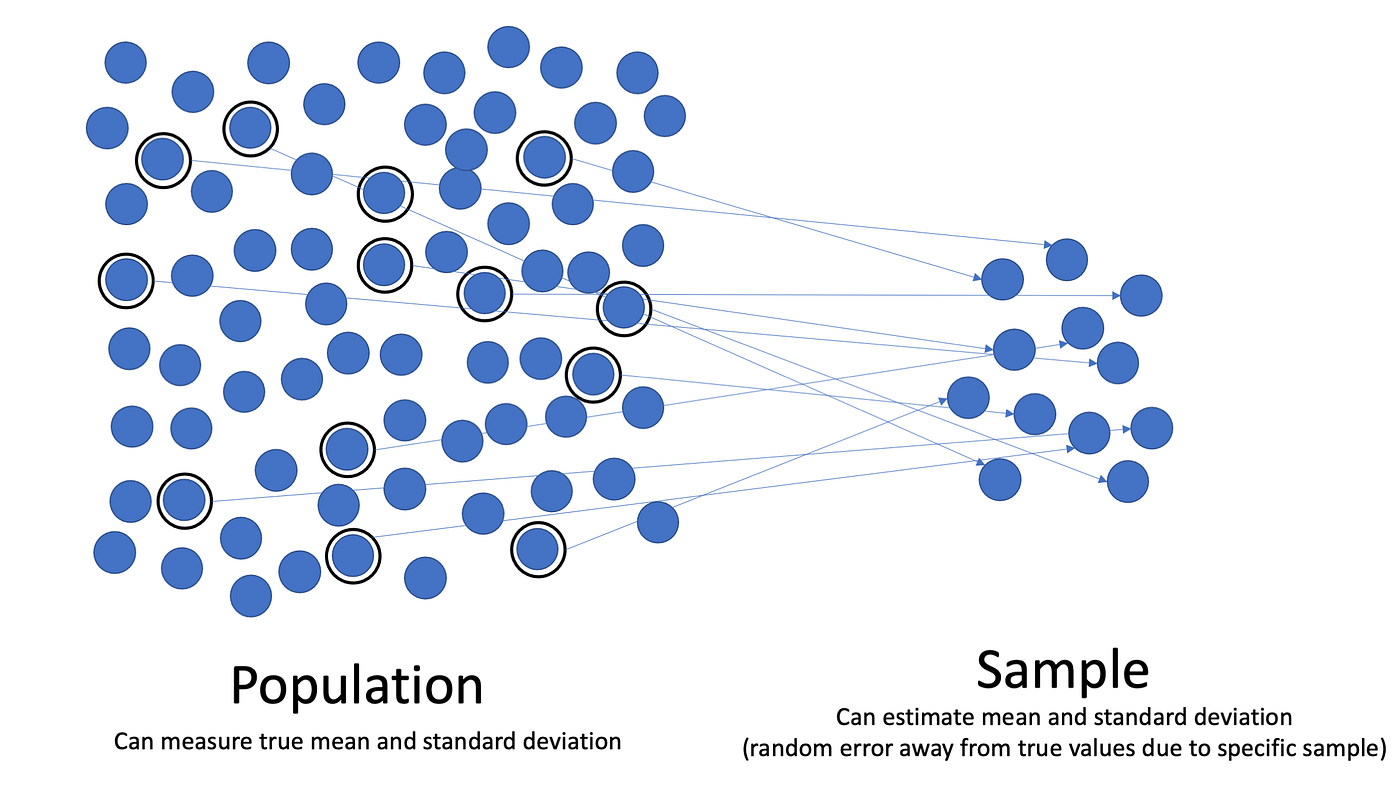
Tetapi masalahnya, kita kan ga tahu varians di populasi? Yang kita tahu, hanya varians di sampel. Terus gimana, dong?
Statistik adalah soal embracing uncertainty (..and that’s the beauty of it!). Peneliti memang tidak tahu (…dan tidak akan pernah tahu) apa yang terjadi di populasi. Tetapi kita bisa tahu seberapa mungkin temuan penelitian akurat/meleset.

Estimasi soal akurasi temuan survei ini dapat diketahui melalui dua indikator; 1) standard error — yaitu seberapa besar variasi yang mungkin terjadi kalau ambil data lagi di sampel yang sama; dan 2) margin of error — yang menunjukkan “seberapa meleset” temuan penelitian merefleksikan kondisi populasi.
Itulah kenapa lembaga survei selalu mencantumkan margin of error dalam rilis publik mereka.
In defense of Tim Riset Kesejahteraan Dosen😏
Dengan primer yang sudah saya jabarkan sebelumnya, yuk coba kita periksa seberapa akurat temuan dari hasil survei ini.
Di survei disebutkan bahwa 42.9% dosen mendapatkan penghasilan tetap di bawah Rp3 juta — setelah bertanya pada 1,196 partisipan.
Dari data ini, kita bisa hitung standard error of proportion (SE). Hitungan saya, SE-nya ketemu 1.4%.
Kita asumsikan distribusi populasi mengikuti distribusi normal, maka untuk menghitung margin of error, maka SE tadi dikalikan 1.96 — yang sudah baku (z) untuk taraf kepercayaan sebesar 95%. Alasannya, toleransi ketidakpastian yang umumnya diterima oleh peneliti adalah 5%.
Tapi saya mau julid deh sama Tim Riset Kesejahteraan Dosen. Berani-beraninya mereka riset hal sepenting dan seviral ini ga ngajak-ngajak saya😏
Taraf kepercayaan 95% yang umumnya diterapkan peneliti sosial itu ga cukup buat saya. Gimana kalau 99% aja? Bisa dong— kita tinggal kalikan SE dengan nilai z untuk taraf kepercayaan sebesar 99% — yaitu 2.576.
Margin of error klaim di atas berarti 3.7%
Artinya, rentang persentase dosen yang penghasilannya di bawah Rp3 juta sebenarnya di populasi adalah sekitar 39.2% (42.9–3.7) sampai dengan 46.6% (42.9+3.7).
Tetapi, ingat! Rentang kepercayaan yang saya toleransi tadi adalah 99% — artinya, kalau data diambil lagi dari populasi yang sama, infinitely, maka masih ada peluang sebesar 1% persentase yang sesungguhnya di populasi jatuh di luar rentang ini.
Buat saya, this is absolutely within acceptable range. Pun ambil batas bawah dari rentang kepercayaan tadi — 39.2% — masih angka yang besar, lho.
Kalaupun jumlah sampel ditambah, rentang kepercayaan tadi memang akan menyempit — dengan begitu semakin mendekati nilai sesungguhnya di populasi. Tetapi, tidak akan mengubah kesimpulan penelitian, bahwa dosen memang diupah terlalu rendah.
Jadi, keterwakilan tidak penting?
Tidak juga. Keterwakilan itu tetap penting, tetapi seringkali dilebih-lebihkan peranannya dalam menentukan akurasi hasil survei. Mengusahakan keterwakilan itu seringkali kontraproduktif pada tujuan penelitian karena tidak semua penelitian harus bisa digeneralisasi ke populasi.
Teknik probability sampling itu juga dilebih-lebihkan peranannya, karena menurut suatu studi, kesimpulan yang ditarik dari sampel yang diperoleh dengan probability sampling tidak berbeda secara substansial dengan sampel dari nonprobability sampling.
Survei pada dasarnya akan selalu diliputi bias, dan margin of error tadi hanya salah satu dari sekian banyak bias yang mungkin terjadi dalam penelitian survei.
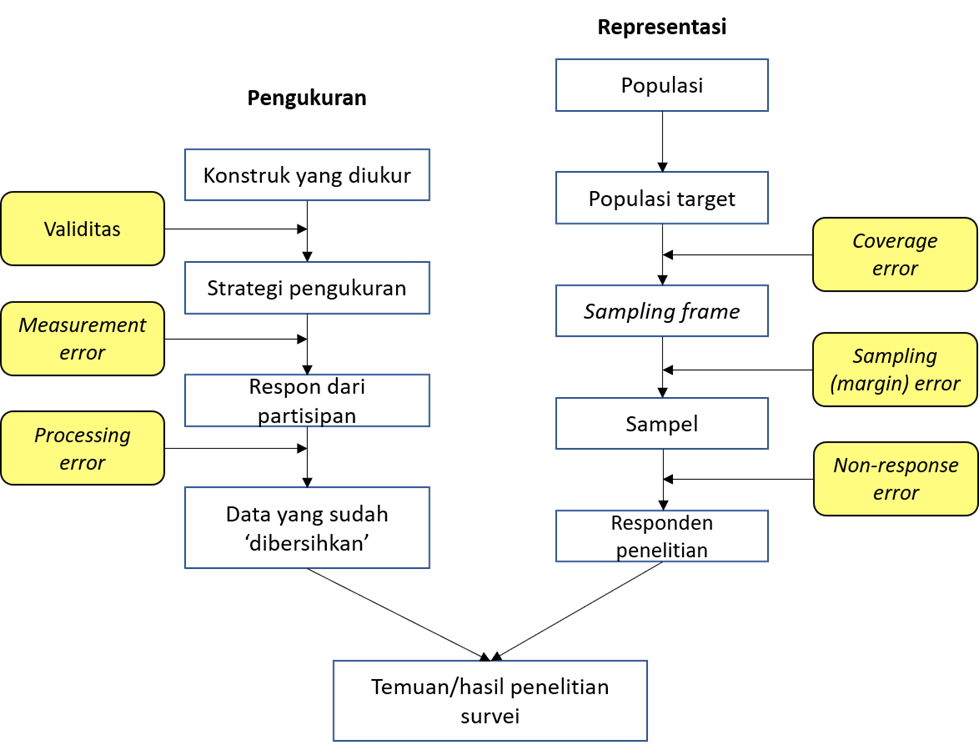
Sesuai dengan gambar di atas, peneliti tidak hanya harus memikirkan soal margin of error, tetapi juga jenis bias yang lain. Konsensus yang umum terjadi di komunitas akademik saya, sampling error ini tidak pernah jadi concern utama peneliti. Mereka lebih kuatir dengan desain penelitian dan measurement error, karena keduanya ini adalah beberapa diantara penyebab utama temuan survei tidak bisa direplikasi.
Jadi kalau ada yang nanya soal teknik sampling, biasanya rekan-rekan saya langsung komentar, “sudah berapa lama bacaan metodologinya gak diupdate?”
Mungkin kita perlu adil dalam mengkritik (?)
Apakah studi Kesejahteraan Dosen ini punya kekurangan?
Tentu ada.
Tim merekrut partisipan melalui media sosial — artinya, partisipan mengajukan diri untuk terlibat (self-selection bias), bukan dipilih oleh peneliti dari proses pengacakan. Tetapi, untuk melakukan proses sampling, harus ada sampling frame. Untuk dosen, berarti sampling framenya mungkin data PDDikti.
Memangnya tim kroco mumet ini punya akses untuk lihat data lengkap PDDikti? Mendapatkan pendanaan untuk melakukan riset ini aja engga, lho. Seratus persen voluntary. Seharusnya, Dikti berterima kasih ke mereka, karena Dikti mendapatkan dasar yang rasional untuk bertindak (kalau mau bertindak sih ya) tanpa mengeluarkan sumberdaya apapun.
Persoalan yang sama juga mungkin terjadi pada survei yang didukung sumberdaya yang banyak. Bisa ngga ada yang menjamin SUSENAS bebas dari selection bias? Jadi, saya sangat mengapresiasi kolega-kolega saya yang sudah bersusah payah mencurahkan tenaga dan waktunya, tanpa dibayar.
Studi ini sudah membawa aspirasi dosen-dosen yang sudah lama diperlakukan tidak adil, menjadi kesadaran publik. Tanpa usaha tim ini, tidak ada upaya untuk mulai membicarakan soal upah yang layak untuk dosen.
Pernyataan kemungkinan adanya konflik kepentingan
Saya kenal secara personal dengan anggota tim Riset Kesejahteraan Dosen sehingga mungkin saja ada bias kedekatan personal yang mendorong saya untuk menulis in defense of temuan riset mereka. Tetapi argumen saya di atas bisa discrutinize sama-sama.
—-
Artikel ini terbit pertama di https://medium.com/@ameliazein/survei-harus-representatif-benarkah-61bd396a5faa dengan perubahan minor di paragraf pertama.
